An Introductory Demo Video Showcasing Our Work
Abstract
Video generation models have emerged as a promising paradigm for embodied world simulation. However, both general-domain video generators and robot-specific fine-tuned models can still produce physically implausible manipulations — including discontinuous motion trajectories and inconsistent robot–object interactions — which limits their reliability as world simulators. Through extensive experiments, we find that such physical instability mainly arises from two factors: deformation of moving objects and implausible spatio-temporal correlations among interacting entities. Specifically, generated motion trajectories often exhibit severe object deformation, while the physical relations between objects — particularly during interactions — frequently violate real-world dynamics.
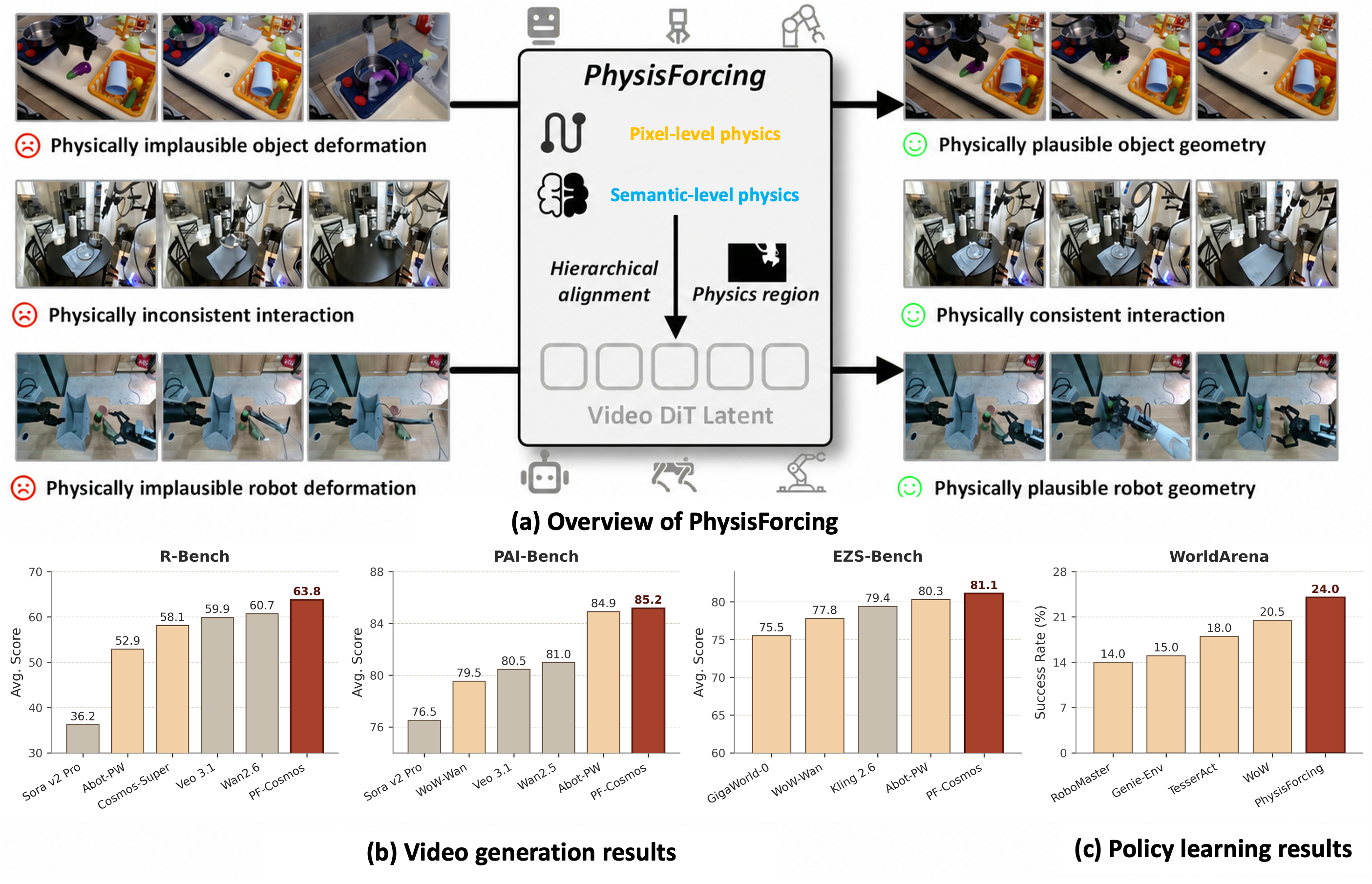
Building on this observation, we propose PhysisForcing, a scalable training framework that strengthens physical consistency by focusing supervision on physics-informative regions through joint optimization of pixel-level and semantic-level features. The framework consists of a pixel-level trajectory alignment loss, which supervises DiT features using reference point trajectories, and a semantic-level relational alignment loss, which aligns DiT features with inter-region relations from a frozen video understanding encoder. Extensive experiments on R-Bench, PAI-Bench, and EZS-Bench show that PhysisForcing consistently improves embodied video generation over strong baselines, lifting the Wan2.2-I2V-A14B and Cosmos3-Nano base models on R-Bench by +22.3% and +9.2% (+7.1% and +3.7% over vanilla finetuning), with the Cosmos3-Nano variant attaining the best overall score. Beyond generation, as a world model under the WorldArena action-planner protocol it raises the closed-loop success rate from 16.0% to 24.0% and further improves downstream policy success, indicating that physically aligned video models yield stronger representations for robotic manipulation.
Performance at a Glance
Applied as a training-time framework on standard diffusion video backbones, PhysisForcing improves physical plausibility over the corresponding base model on every benchmark we evaluate, from embodied video generation to downstream world-action modeling.
Percentages are relative gains of PF-Wan14B over the finetuned Wan2.2-A14B baseline (video benchmarks) and of PF-Wan5B over the finetuned Wan2.2-5B baseline (WorldArena IDM).
Key Contributions
Hierarchical Formulation
We cast physical plausibility as a hierarchical problem and align both pixel-level point trajectories and semantic-level inter-region relations on the DiT feature.
Region-Focused Supervision
A depth-aware motion mask localizes physics-informative regions, concentrating supervision on manipulators, objects, and contacts rather than all pixels uniformly.
No Additional Inference Overhead
All auxiliary models are used only at training and discarded afterwards, so the method adds no additional inference cost while also strengthening downstream policy learning.
Method Overview
PhysisForcing first identifies physics-informative regions where robot–object interactions occur, then applies two complementary training signals on the DiT feature.
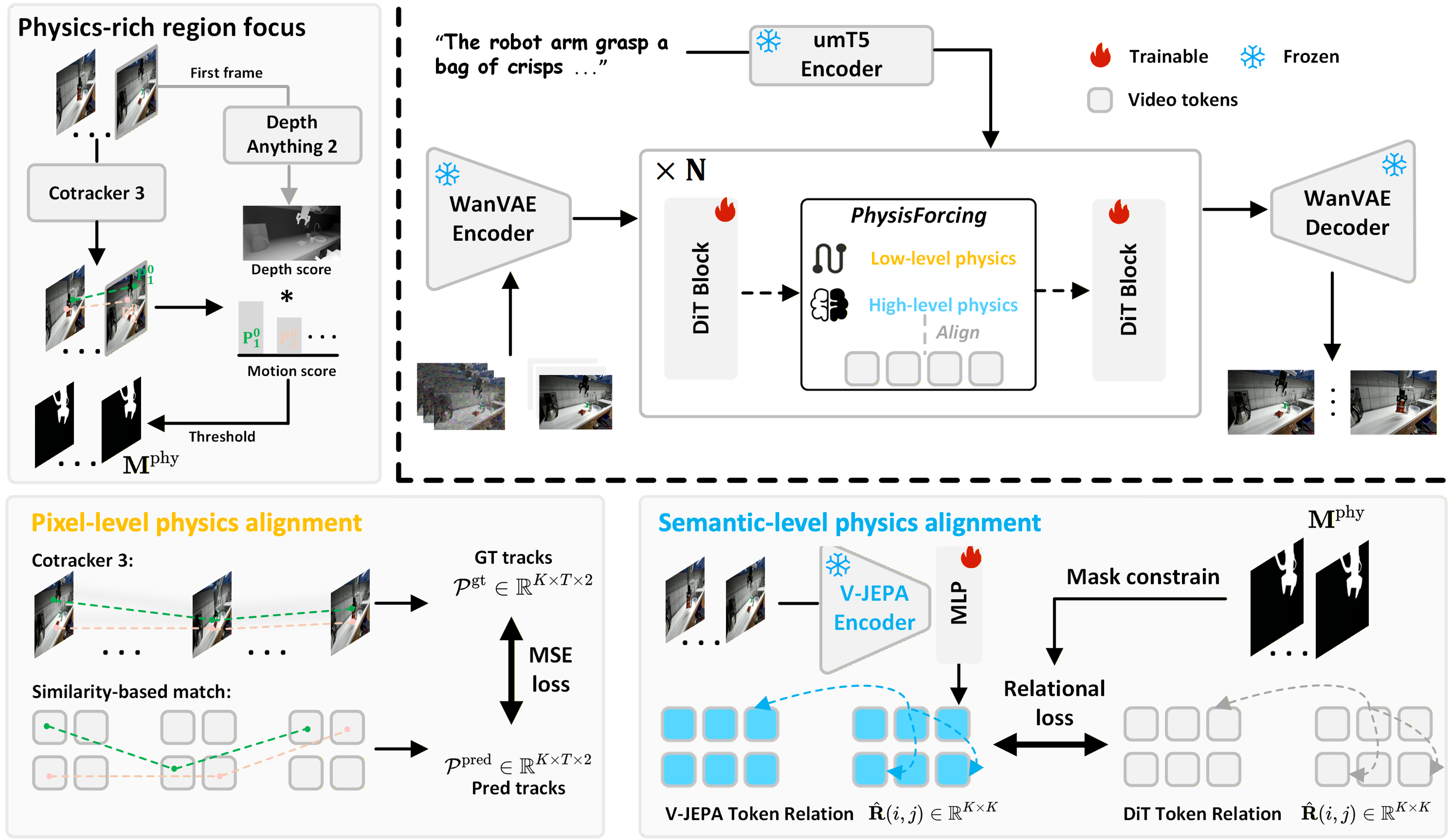
Pixel-level Physics Alignment
Using point tracking (CoTracker3), we supervise the per-point trajectories implied by the DiT feature against dense reference trajectories. A masked MSE over predicted and reference coordinates keeps local motion continuous and contact-compatible on the manipulator and the manipulated object.
Semantic-level Physics Alignment
We align the token-to-token similarity matrix of physics-informative tokens between the DiT side and a frozen self-supervised video understanding encoder. Transferring the encoder's relational structure encourages globally consistent interactions — e.g., a grasped object stays coupled with the gripper, and a pushed object moves away.
From Implausible to Plausible
Given the same input image and prompt, vanilla finetuning still leaves physical violations
— unstable grasps, object drift, broken contact. Adding
PhysisForcing restores physically plausible motion. We show this on two
backbones below.
Hover an input frame to read its full prompt.
Qualitative Comparison
PhysisForcing against five strong video generators on identical inputs, followed by a gallery of
additional generations.
Use the arrows or dots to browse cases.
Video Generation · Cross-Embodiment Generalization
Video Generation · Cross-Task Generalization
More Results from PhysisForcing
Quantitative Results — Video Generation
PhysisForcing applied to two backbones — Wan2.2-I2V-A14B and Cosmos 3-nano — on three embodied video benchmarks. Each table reports the finetuned (ft) baseline and the corresponding + PhysisForcing result against strong external baselines.
| Model | Tasks | Emb. | Avg. |
|---|---|---|---|
| Veo 3.1 | 49.9 | 64.3 | 56.3 |
| Hailuo v2 | 52.0 | 62.0 | 56.5 |
| Cosmos 3-super | 51.2 | 66.7 | 58.1 |
| Seedance 1.5 Pro | 51.9 | 66.5 | 58.4 |
| Wan 2.6 | 54.5 | 68.4 | 60.7 |
| Abot-PhysWorld | 48.9 | 57.9 | 52.9 |
| Wan2.2-A14B | 40.8 | 63.2 | 50.7 |
| Wan2.2-A14B (ft) | 52.5 | 64.7 | 57.9 |
| PF-Wan14B | 56.3 | 69.0 | 62.0 |
| Cosmos 3-nano (ft) | 55.4 | 69.1 | 61.5 |
| PF-Cosmos | 58.2 | 71.0 | 63.8 |
| Model | Quality | Domain | Avg. |
|---|---|---|---|
| Wan 2.5 | 75.48 | 86.44 | 80.96 |
| GigaWorld-0 | 75.91 | 85.83 | 80.87 |
| Veo 3.1 | 77.40 | 83.50 | 80.45 |
| WoW-Wan 14B | 76.05 | 83.01 | 79.53 |
| Sora v2 Pro | 76.79 | 76.26 | 76.52 |
| Abot-PhysWorld | 76.76 | 93.06 | 84.91 |
| Wan2.2-A14B | 76.15 | 81.70 | 78.93 |
| Wan2.2-A14B (ft) | 75.38 | 84.42 | 79.90 |
| PF-Wan14B | 76.26 | 88.20 | 81.73 |
| Cosmos 3-nano (ft) | 76.52 | 91.54 | 84.03 |
| PF-Cosmos | 77.08 | 93.26 | 85.17 |
| Model | Quality | Domain | Avg. |
|---|---|---|---|
| WoW-Wan 14B | 76.09 | 79.51 | 77.80 |
| GigaWorld-0 | 72.72 | 78.26 | 75.49 |
| Cosmos-Predict 2.5 | 70.89 | 76.98 | 73.94 |
| UnifoLM-WMA-0 | 73.55 | 52.32 | 62.94 |
| Kling 2.6-Pro | 78.05 | 80.72 | 79.39 |
| Abot-PhysWorld | 76.94 | 83.66 | 80.30 |
| Wan2.2-A14B | 76.89 | 77.42 | 77.16 |
| Wan2.2-A14B (ft) | 76.12 | 81.95 | 79.04 |
| PF-Wan14B | 76.58 | 84.49 | 80.54 |
| Cosmos 3-nano (ft) | 77.42 | 83.16 | 80.29 |
| PF-Cosmos | 76.95 | 85.20 | 81.08 |
Quantitative Results — Policy Learning
PhysisForcing as a video backbone for world-action modeling: closed-loop success on RoboTwin 2.0 (Fast-WAM) and on the WorldArena action-planner (IDM) protocol (Wan2.2-5B).
| Task | Fast-WAM | + PF | Δ |
|---|---|---|---|
| place_empty_cup | 41.5% | 63.0% | +21.5% |
| press_stapler | 49.0% | 60.0% | +11.0% |
| grab_roller | 58.5% | 63.0% | +4.5% |
| shake_bottle | 97.5% | 94.5% | −3.0% |
| adjust_bottle | 93.0% | 93.0% | 0.0% |
| stack_bowls_two | 69.5% | 63.0% | −6.5% |
| Average | 68.2% | 72.8% | +4.6% |
| Model | Task 1 | Task 2 | Avg. |
|---|---|---|---|
| Genie Envisioner | 10.0% | 20.0% | 15.0% |
| TesserAct | 1.0% | 35.0% | 18.0% |
| RoboMaster | 8.0% | 20.0% | 14.0% |
| Vidar | 2.0% | 19.0% | 10.5% |
| WoW | 20.0% | 21.0% | 20.5% |
| Wan2.2-5B (base) | 12.0% | 20.0% | 16.0% |
| PF-Wan5B | 22.0% | 26.0% | 24.0% |
Ethics Concerns
All videos featured in these demos are either generated by models or sourced from publicly available datasets, and are intended solely for the purpose of demonstrating the technical capabilities of our research. If you believe any content infringes upon rights or raises ethical concerns, please contact us and we will address the issue and remove the material promptly.
BibTeX
@article{physisforcing2026,
title = {PhysisForcing: Physics Reinforced World Simulator for Robotic Manipulation},
author = {Peiwen Zhang and Yufan Deng and Shangkun Sun and Juncheng Ma and Duomin Wang and Jonas Du and Zilin Pan and Ye Huang and Hao Liang and Songyan Huang and Ruihua Zhang and Enze Xie and Ming-Yu Liu and Daquan Zhou},
journal = {arXiv preprint arXiv:2606.28128},
year = {2026}}